그래서 redis cluster hash slot은 무엇인가?
hash slot은 redis cluster의 node간에 key 분산 방법이다. nosql의 key 분산 방법의 기초가 되는 consistent hashing도 함께 알아본다.
redis cluster
redis cluster은 redis 3.0 버전 이상부터 추가되었으며 데이터 동기화, 복제, failover 등을 지원할 수 있는 기능이 추가된 향상된 redis라고 생각하면 된다. 특히 failover 관점에서 node의 장애 또는 통신 문제 등 master-slave 및 replica 기능을 통해 수준높은 가용성을 제공할 수 있다.
nosql은 각 node에 key를 할당할 때 특정 node에 집중되지 않고 분산처리를 위해 consistent hashing 이라고 하는 파티셔닝 방법을 대게 사용한다. consistent hashing은 redis 3.0 이전에는 다양한 버전에서 채택했다. 이후 redis cluster가 자리잡으면서 hash slot 이라는 방법을 선택했다.
hashing
분산처리 key 분배 시 기본적으로 hasing에 의해 값을 결정하고 목적에 따라 일부 알고리즘을 변경해서 사용한다. 일단 redis cluster hash slot 설명에 앞서 key 분산처리를 위한 일반적인 hashing 및 consistent hashing을 먼저 알아보자.
general hashing
먼저 일반적인 hashing 방법에 의해 key를 분산하면 어떻게 될까? 간단하게 알아보자.
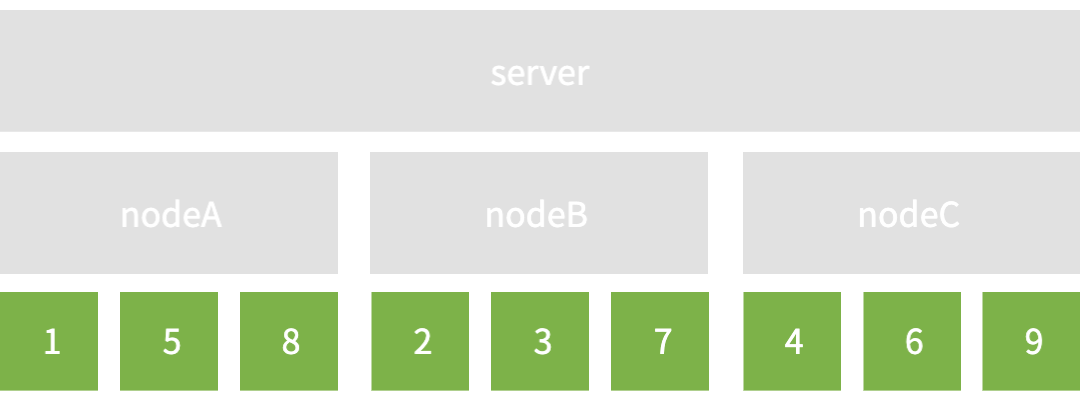
- node: 3(nodeA~C)
- key: 9(key1~9)
key가 유입되면 특정 hash(key) 함수의 결과에 의해 특정 node로 결정된다고 가정한다. 3개의 node에 9개 key를 분산 시켰을 때 모습을 보자. 일단 아름답게 잘 분산되어 있도록 가정했다. 편-안
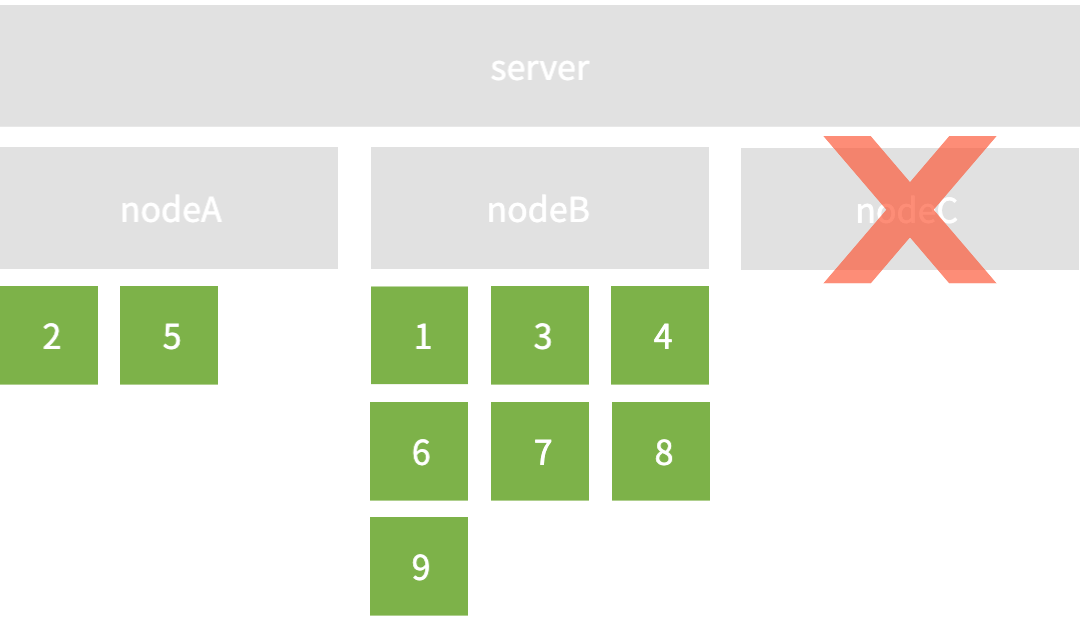
만약 nodeC가 장애 또는 서버통신 문제로 제기능을 할 수 없는 상태가 되었다고 하자. 그렇다면 nodeC에 분산된 key는 어떻게 될 것인가? 마음같아선 nodeA, B에 동일하게 하나씩 나눠주고 싶겠지만 결국 최초 정해진 분산 방법에 따라 전체 재해싱을 진행할 수 밖에 없다. 재해싱 후 nodeB, B의 평화에 곧 엄청난 불균형이 찾아왔다. 이는 곧 재해싱 만으로도 server에 부하를 가져오지만, 각 node 간의 key 불균형도 피할 수 없다.
그래서 고안된 방법 중 하나인 consistent hashing 을 소개한다. 관련 논문은 이곳에서 볼 수 있다.
consistent hashing
consistent hashing은 node의 수에 의존하지 않고 추가/삭제된 node가 있을때 재분산 해야하는 key의 수를 최소화 하기 위한 방법이다. hash ring이라 불리는 추상적인 원 또는 링 형태에 CRC-32(2^32)라고 하는 hash 연산의 결과에 따라 node를 할당하고, 인입되는 key에 대해서 동일한 hash 연산을 통해 어떤 node에 배치할 지 결정해주는 key 분산 처리 방법이다. 코드와 시나리오를 보며 이해 해보자.
kotlin
data class Node(val id: String)
class ConsistentHash(private val numberOfReplicas: Int, private val nodes: Set<Node>) {
private val circle = HashMap<BigInteger, Node>()
init {
for (node in nodes) {
add(node)
}
}
fun add(node: Node) {
for (i in 0 until numberOfReplicas) {
val digest = MessageDigest.getInstance("MD5").digest((node.toString() + i).toByteArray())
val hash = BigInteger(1, digest).mod(BigInteger.valueOf(2).pow(32))
circle[hash] = node
}
}
fun remove(node: Node) {
for (i in 0 until numberOfReplicas) {
val digest = MessageDigest.getInstance("MD5").digest((node.toString() + i).toByteArray())
val hash = BigInteger(1, digest).mod(BigInteger.valueOf(2).pow(32))
circle.remove(hash)
}
}
fun getNode(key: String): Node {
if (circle.isEmpty()) return throw BadRequestException("circle is empty.")
val digest = MessageDigest.getInstance("MD5").digest(key.toByteArray())
val hash = BigInteger(1, digest).mod(BigInteger.valueOf(2).pow(32))
val nodes = circle.keys.sorted()
var node = nodes.firstOrNull { it >= hash }
if (node == null) node = nodes.first()
return circle[node]!!
}
}
fun main() {
val ch = ConsistentHash(
numberOfReplicas = 1,
nodes = setOf(
Node("A"),
Node("B"),
Node("C"),
)
)
val nodeOfKey = mutableMapOf<Node, MutableSet<String>>()
(1..9).forEach {
val key = "key$it"
val node = ch.getNode(key)
if (nodeOfKey.containsKey(node)) {
nodeOfKey[node]!!.add(key)
} else {
nodeOfKey[node] = mutableSetOf(key)
}
}
val sortedMap = nodeOfKey.toSortedMap(compareBy { it.id })
sortedMap.forEach {
println("${it.key.id}: ${it.value}")
}
}- node: 3(nodeA~C)
- key: 9(key1~9)
- replica: 1(여기서 1은 별도의 복제 없이 node의 수와 동일함을 뜻함)
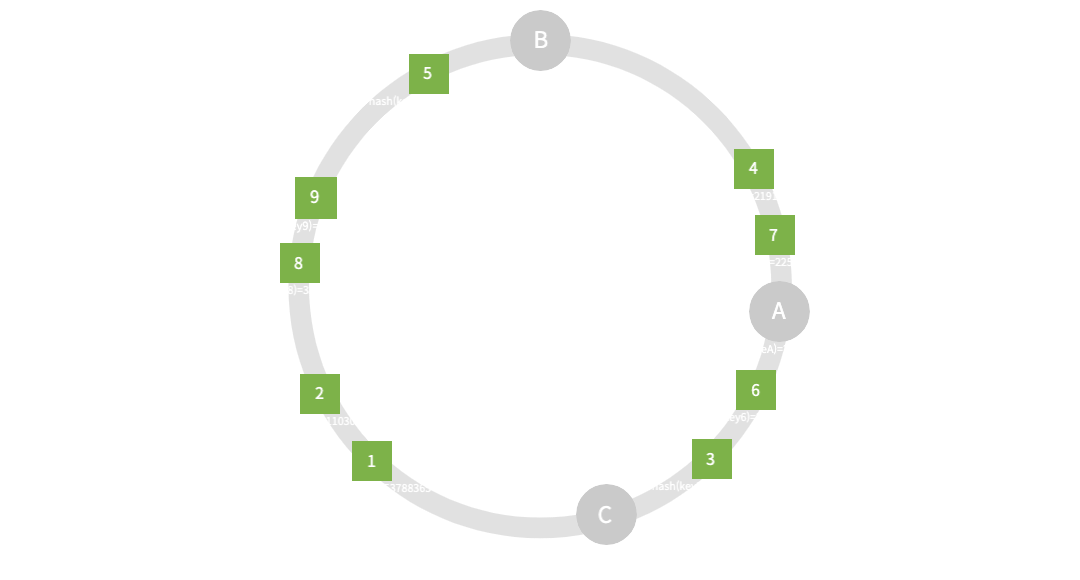
nodeA: [key4, key7]
nodeB: [key1, key2, key5, key8, key9]
nodeC: [key3, key6]
코드의 실행결과는 print 값은 위와 같으며, 이를 그림으로 표현한 모습이다. 원리는 간단하다.
코드에 표현되어 있듯, 입력된 position = hash (key) mod (2 ^ 32) 연산에 의해 위치가 결정되며, 이때의 위치는 시계방향 기준으로 가까운 node를 따라가도록 되어있다.
그리고 hash 값이 가장큰 nodeC의 값을 넘을 경우 첫번째 nodeA를 바라보도록 되어있기 때문에 결국 원형 또는 링의 모습을 띄도록 그릴 수 있는 것이다.
그렇다면 이번에도 nodeC가 장애 또는 네트워크 이슈로 인해 key의 재분산이 필요하다면 어떠할까?
- node: 2(C는 장애)
- key: 9
- replica: 1
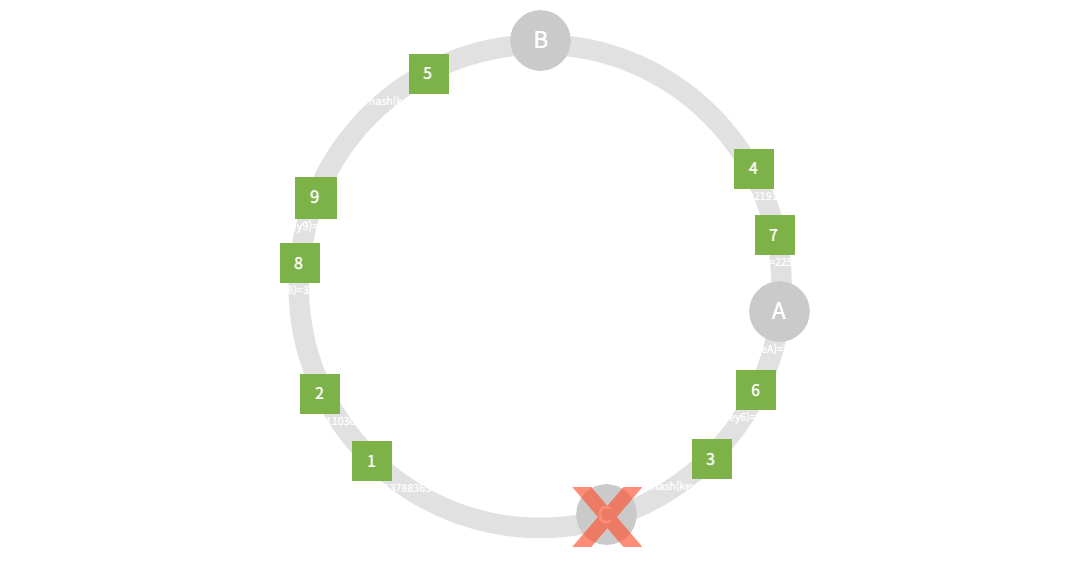
nodeA: [key4, key7]
nodeB: [key1, key2, key3, key5, key6, key8, key9]
결과는 어느정도 예상해볼 수 있다. 시계방향으로 위치할 node가 결정나므로 key3, 6은 자연스럽게 nodeB에 재분산 된 모습이다. 하지만 결과론적으로 안타깝지만 일반적인 hashing과 같이 nodeA, B는 또다시 불균형을 피하지 못했다. 그래도 다행이라면 재해싱 및 재분산이 아닌 서버의 추가/장애에 영향을 받는 node의 key만 재분산 하면 된다. 모두 고생할 필요는 없다. 그렇게 어느정도의 부하는 줄일 수 있었지만 여전히 불균형이 존재한다. 이를 위해 고안된 방법이 바로 가상의 복제 node(vnode)를 배치하는 방법이다. replica의 수를 3으로 설정하여 기존 node들의 가상 복제본을 각각 2쌍 추가하며, 동일한 hash 연산에 따라 replica node를 위치한다.
- node: 2(C는 장애)
- key: 9
- replica: 3
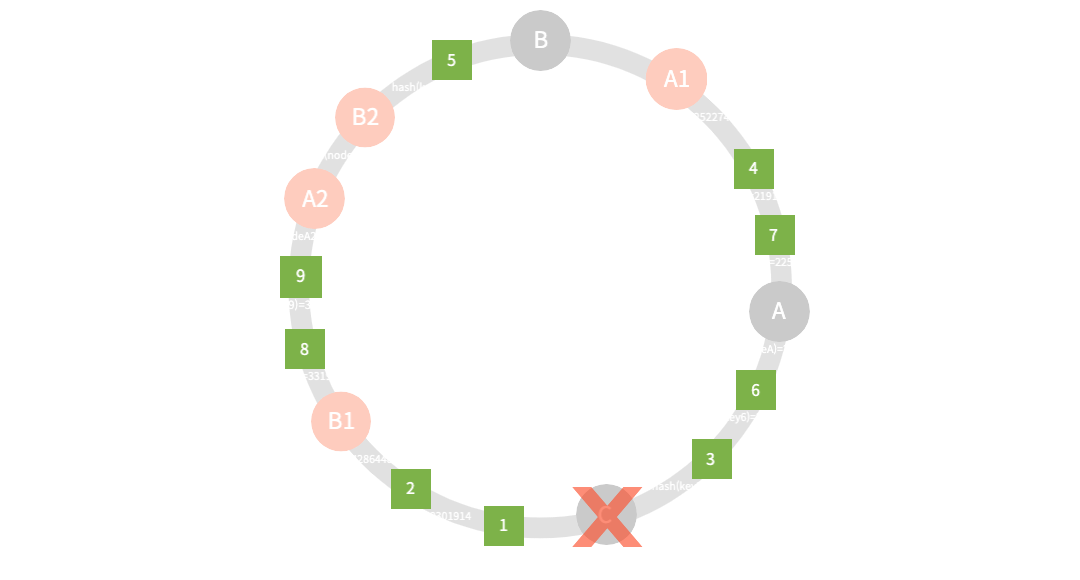
nodeA: [key4, key7, key8, key9]
nodeB: [key1, key2, key3, key5, key6]
replica node들에 의해 다시 균형이 찾아왔다. print 결과를 보면 제대로 분산 되어 있다. nodeA, B 집군에 복제된 A1~2, B1~2가 각각 hash 결과에 따라 위치하여 원형링에서 분산 node의 역할을 수행하게 된다. replica의 수가 증가하면 node의 간격은 더더욱 촘촘해져, key 분산 배포는 더욱 균일해질 확률이 높다. 그렇다고 무조건 높다고 좋다는 것은 아니다. 이에 대한 설명은 따로 하지 않겠다. (과유불급)
이렇듯 consistent hashing에서는 node의 추가/장애 간에 발생할 수 있는 key 불균형을 가상의 복제본 서버를 도입하는 방법으로 해결할 수 있으며, 이를 통해 cache node 수의 변경에 상관 없이 높은 수준의 히트율과 고가용성을 보장한다. 이는 분산 캐시, 분산 스토리지, 분산 요청 등 다양한 영역에서 사용된다.
redis 3.0 이후 redis cluster가 도입되면서 hash slot에 의해 key를 관리하게 된다. 그렇다면 hash slot은 어떻게 동작할까?
hash slot
hash slot은 consistent hashing과 비슷한 개념을 redis cluster에서 일컫는 방법이라 생각하면 된다. 하지만 구체적인 구현에는 조금 차이가 있다.
HASH_SLOT = CRC16(key) mod 16384
redis cluster는 총 16384개의 key space를 갖고, 이를 위해 16384 mode 연산의 결과로 key를 slot에 할당한다. slot의 갯수를 16384로 제한한 이유는 이곳에서 설명하고 있으며, 결국 효율적인 key 분산을 위한 설정으로 보인다. 이에따라 cluster는 최대 1000개의 master node를 갖을 수 있도록 제한하고 있다. 그렇다면 hash slot은 어떻게 node와 key를 관리하는지 확인해보자.
- node(master): 3
- replica(slave): 1
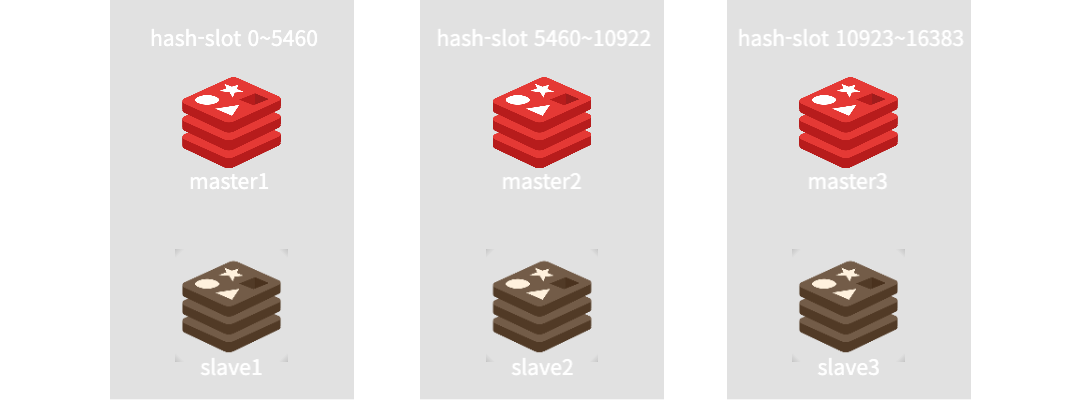
redis cluster는 node의 갯수에 따라 16384라는 정해진 slot을 node갯수만큼 나누어(N빵) 각 key에 대한 hash연산 결과에 따라 slot에 기록한다. 예시를 위해 master node는 3개 세팅하였다. 실제로 0~16384의 slot을 가진 하나의 node로 구성해도 무관하다. 다만 redis cluster에서는 master node에 하나 이상의 slave node를 배치해야한다. 이번에는 replica를 1로 하여 하나의 salve만 구성한다. 이렇게 redis cluster의 replica를 구성하게 되면 slave node는 자신의 master와 다른 slot에서 각자의 master node를 바라보도록 구성한다.
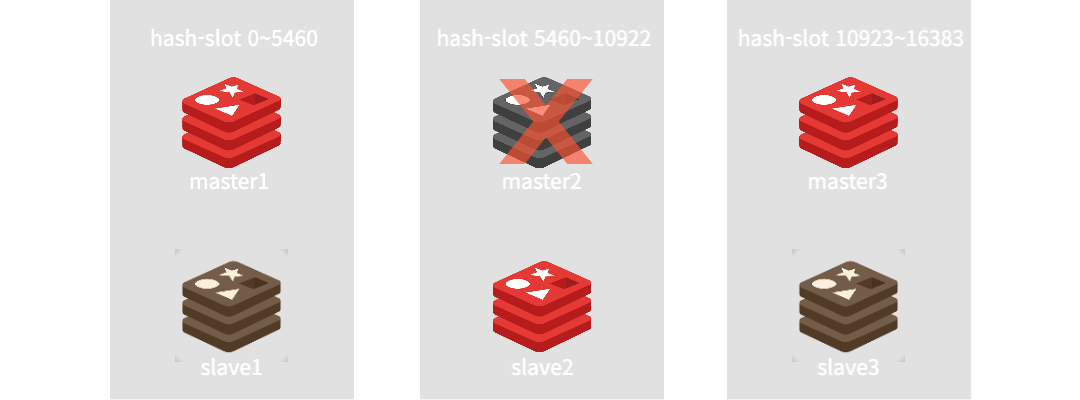
그렇다면 이번에도 node 하나가 장애가 발생하면 어떻게 될까? redis cluster는 서로 node들 간에 통신을 하며 연결되어 있고, 지속적으로 서로의 상태를 살피며 cluster을 관리한다.
그러므로 장애 발생시 상황을 전파받고, 해당 장애가 발생한 node의 slot을 파악한 후, slave에게 master의 역할을 승격하여 failover 할 수 있도록 구성되어있다.
이후 해당 node의 조치가 완료되면 다시 원래 상태로 돌아온다. 하지만 장애가 발생한 slot의 master, slave가 모두 장애가 발생한다면 이때는 재기능을 못할 수 있다. 이것은 redis cluster의 failover와 별개로 node를 잘 구성해야하는 문제다.
이렇듯 redis cluster는 서로간에 통신하며 master/slave 자가복구 기능이 있어 sentinel과 같은 HA(high availability) 도구가 필요 없다.

장애난 node가 복구되고, node 한대를 추가한다고 하자. 총 4개의 node가 slot을 할당받은 모습이 그려진다. 이는 node의 slot이 이제 slot range = 16384 / 4 의 결과로 재구성할 수 있게 되는것이다.
그렇다면 기존에 존재한 key는 전부 재분산 처리를 해야하는가? 아니다. 결국 동일한 hash 연산에 mod 16384 이라는 정해진 slot 갯수로 나누기 때문에 이미 slot을 할당 받은 key의 hash값은 변하지 않는다.
즉 최초에 slot이 1429로 정해진 key는 1번 node에 위치할 것이며, node가 추가되어도 연산 결과가 바뀌지 않아 slot의 위치는 동일하다는 뜻이다.
그외 추가된 node에 의해 영역의 갭이 생긴 4094개의 slot의 key들만 영향을 받을 수 있다. 이렇게 redis cluster에서는 key의 전체 재분산을 하지 않고 node가 추가 되었을때 최소한의 분산을 지원할 수 있다.
그리고 slot 전체를 재분산하려면 reblance 명령어를 통해 slot간에 key 재분산이 가능하다.
그래서?
그래서 구체적인 구현 방식에서 차이는 조금 있지만 redis cluster의 hash slot과 consistent hashing은 둘 다 key-value 쌍을 관리하는 분산 캐시 시스템에서 사용되는 hashing 기법이다.
결국 분산 캐시 시스템에서의 핵심은 hash. 적절한 hash function을 통한 연산 결과 값을 어떻게 다루느냐 성능과 가용성을 좌우한다.
ref.
- https://severalnines.com/blog/hash-slot-vs-consistent-hashing-redis/
- https://en.wikipedia.org/wiki/Consistent_hashing#History
