그래서 elasticsearch shard 값은 왜 변경이 불가할까?
결론부터 얘기하면 기생성된 index의 shard 값을 변경하지 못하는 이유는 lucene(루씬) 때문이다. lucene과 이를 구성하고 있는 segment shard와 함께 얘기한다.
lucene
lucene은 elasticsearch의 핵심이 되는 검색엔진 그 자체이며, java로 만들어진 고성능 정보검색 오픈소스 라이브러리이다. 결국 elasticsearch는 검색 및 색인 기능은 직접 구현한게 아닌 lucene을 사용한 것이다. 그 외 REST api, 분산처리, 고가용성을 위한 shard/replica 등의 시스템을 추가하여 지금의 elasticsearch 스펙이 완성된 것이다.
segment
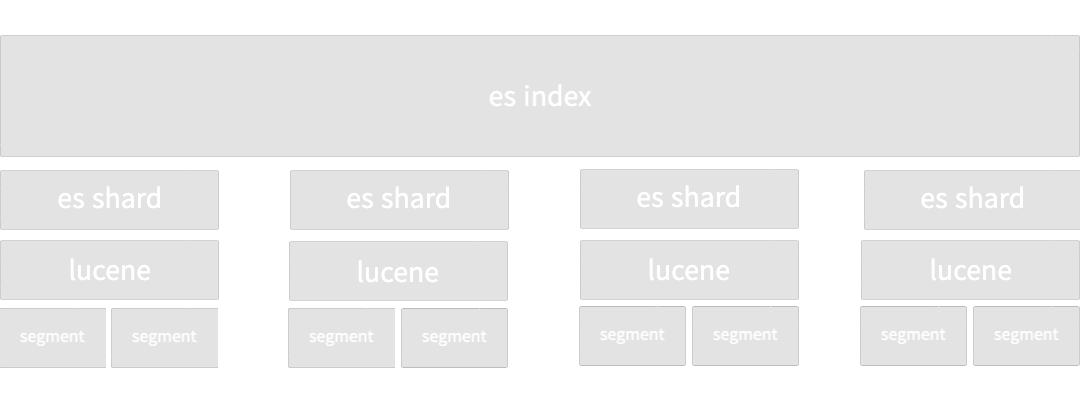
es의 index는 es shard 내 각자 lucene 라이브러리를 포함하고 있으며, lucene은 각각 독립적인 segment를 구성하고 있다. segment는 색인이 될 때 마다 새롭게 만드는 형태로 개발되어있다. 이때 segment는 내부에 역색인 구조로 데이터가 저장되어 있으며, lucene은 commit point라는 자료구조를 통해 segment들을 관리한다. 새로운 색인 작업이 생길때마다 segment를 새로 생성하며, 이를 commit point에 기록하는 형태이다.
시스템에 따라 다를 수 있지만 대부분의 검색엔진을 사용하는 시스템은 새롭게 색인하는 데이터가 많다. 그때마다 segement 수는 빠르게 계속 증가할 것이다. 이때 너무 많은 segment가 생성되어 있으면 읽기 성능이 저하된다. 이를 방지하기 위해 lucene의 background에서 주기적으로 merge하는 과정이 수행된다. 이를 통해 segement 수를 조정하고, 읽기 성능을 안정적으로 지원할 수 있도록 한다. 이러한 주기적인 merge 과정이 있는 이유는, lucene은 한번 저장된 segment를 수정할 수 없도록 설계되었기 때문이다. 즉 주기적인 merge 작업에 의해 segment가 통합, 삭제 되기 전까지는 수정을 허용하지 않는 것이다. 그렇다면 segment는 왜 이런 immutability(불변성)의 특성을 갖도록 개발된 것일까?
segment immutability
불변성은 역색인으로 생성된 segment들로 구성된 lucene의 입장에서는 매우 중요하다. 대용량 text를 다뤄야하는 역색인 구조에서는 이러한 불변성이 주는 장점이 매우 큰 역할을 하기 때문이다.
-
동시성 문제
데이터의 불변성이 보장된다면 멀티스레드 환경에서 lock이 필요없다. 수정이 불가능한 데이터는 스레드간의 충돌이 없을 뿐만 아니라 시스템이 단순해지고, 자연스럽게 성능적인 이점을 얻을 수 있다. -
캐시 활용
데이터가 변경되지 않기 때문에 시스템에 생성되면 일정시간 유지된다. 만약 불변성이 보장되지 않는다면 데이터가 변경될 때마다 캐시를 갱신하는 등의 작업이 추가될 수 있는 비용이 포함될 수 있다. 그래서 불병성을 통해 성능적 이점 뿐 아니라 메모리 read를 통한 높은 캐시 hit를 꽤할 수 있다.
그렇다고 장점만 존재하는것은 아니다. 불변성이라는 특성이 곧 수정이 불가하다는 뜻이다. 그말은 즉슨 일부 데이터가 변경되더라도 역색인 구조를 전부 다시 만들어야 한다는 의미이다. 하지만 매 색인마다 전체 역색인을 실시간으로 처리할 수 없다. 그래서 segment는 commit -> merge의 과정을 통해 생성, 통합 되는 것이다. 검색이라는 도메인 특성상 write보다 read 연산의 비중이 크기 때문에 불변성이 가져올 수 있는 장점이 단점보다 중요하다 생각되어 이러한 불변의 구조를 채택한 것으로 보인다.
shard 값 변경
shard는 내부에 독립적인 lucene 라이브러리를 포함하며, lucene은 단일 머신 위에서만 동작하는 stand alone 검색엔진이다. 실제로 es로 검색 요청이 오게되면 1개의 query로 부터 1개의 shard로 시작하여 1개의 thread로 처리가 된다. 즉 lucene은 하나의 검색요청에 대해 별도의 처리 시스템을 갖는 개념이며, 이러한 특성 상 shard 내부의 lucene 입장에서는 함께 es index를 구성하고 있는 다른 shard의 존재를 알 수 없다. 즉 primary shard 갯수를 변경한다는 것은 각각의 독립적인 구조로 되어있는 lucene의 데이터를 모두 재구성 한다는 뜻이다. 하지만 위에서 얘기한 것처럼 lucene의 내부에는 다수의 segment로 이루어져 있고, 만약 쪼개어진 shard의 데이터를 처리하게 된다면 lucene은 역색인된 segement 조각들을 다시 재결합하고 색인하는 등의 리소스가 더 큰 작업이 소요될 것이다. 그래서 한번 생성된 index의 shard의 값은 변경하지 못하도록 막은 것이다.
그래서?
그래서 index 생성 후 shard 변경을 하지 못하는 이유에 대한 의견은 아래와 같다.
elasticsearhc는 단일 머신에서 동작하는 lucene과 불변성의 특징을 살려 설계된 segment에 대한 장점을 살리기 위해 index가 생성된 후 shard 값을 변경할 수 없도록함
그리고
_reindex API를 활용하면 index를 활용하면 shard의 값을 변경할 수 있도록 es에서 제공한다고 한다. 참고로 나는 shard 값 조정 시, 새로운 index를 생성/색인하고 alias를 교체하는 형태로 밖에 처리해보지 않았다. reindex API는 다음에 한번 사용해 봐야겠다.
ref.
- https://brunch.co.kr/@alden/39
- https://jaemunbro.medium.com/elastic-search-%EC%83%A4%EB%93%9C-%EC%B5%9C%EC%A0%81%ED%99%94-68062271fb64
- https://fdv.gitbooks.io/elasticsearch-cluster-design-the-definitive-guide/content/a-few-things-you-need-to-know-about-lucene.html
- https://blog.naver.com/occidere/222855956229
- https://icarus8050.tistory.com/51
