그래서 elasticsearch shard, replica 값은 어떻게 설정할까?
elasticsearch를 운영하기 위해서는 shard와 replica 갯수를 적절히 설정해야한다. 또한 index에 설정된 shard 수는 한번 설정하면 변경이 불가하기 때문에 운영중에 index를 변경하는 번거로움을 덜기 위해서는 적절하게 갯수를 선정하는 것이 중요하다. 그렇다고 한번 설정한 shard는 정답이 아니다. 시스템이 커지고 변경됨에 따라 언제든 변경의 여지를 두고 지켜봐야할 대상이다. 그래서 shard와 replia의 값 설정 기준에 대한 이야기를 한다.
shard
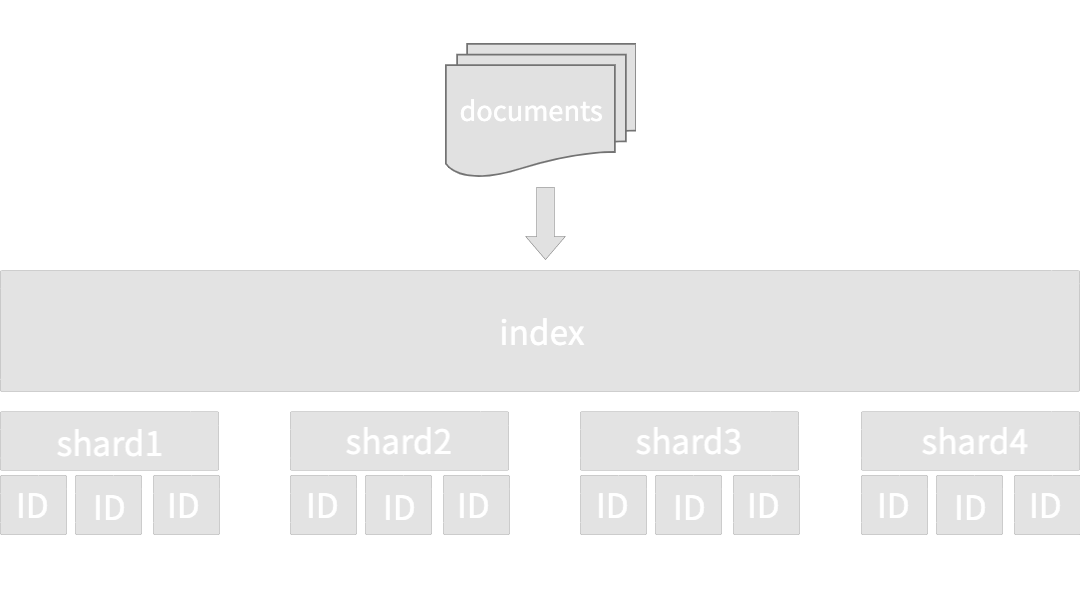 shard는 mysql과 같은 RDB를 기준으로 partition과 같은 의미로, 데이터를 저장할 때 나누어진 조각 단위라고 생각하면 된다. 즉 shard의 데이터는 복사본이 아닌 저장한 데이터 그 자체이다. elasticsearch에서는 충분히 크기가 큰 데이터를 가진 index의 데이터를 특정한 파티션 단위로 나누며, 이를 shard라고 부른다. 각 document 문서는 해당 문서의 hash 값을 통해 계산된 shard로 라우팅 된다. 그리고 일반적으로
shard는 mysql과 같은 RDB를 기준으로 partition과 같은 의미로, 데이터를 저장할 때 나누어진 조각 단위라고 생각하면 된다. 즉 shard의 데이터는 복사본이 아닌 저장한 데이터 그 자체이다. elasticsearch에서는 충분히 크기가 큰 데이터를 가진 index의 데이터를 특정한 파티션 단위로 나누며, 이를 shard라고 부른다. 각 document 문서는 해당 문서의 hash 값을 통해 계산된 shard로 라우팅 된다. 그리고 일반적으로 shard라고 하는 것이 primary shard를 뜻한다. 복사되지 않은 CRUD의 주체가 되는 실제 원본 데이터를 뜻한다.
shard 값 설정
shard 하나의 크기는 일반적으로 최대 50GB이하, 통상적으로 20~40GB 정도 선을 유지하기를 권고하고 있다. 이는 elasticsearch 공식 문서에서 가이드한 값이기도 하며 통상적으로 많은 개발자들이 검증을 한 값이므로 신뢰도가 높다. 하지만 무엇이든 본인의 상황에 맞게 대입하면 된다. 적은량의 데이터를 핸들링할 경우 최소 2개 이상의 node에 shard를 1대만 두고 replica만 세팅해도 상관은 없는 것이다. 다만 primary shard를 결정하는 shard의 값만 많이 설정하고, replica를 적절히 설정하지 않으면 장애발생에 대한 fail-over에 대응이 불가할 수 있으며, 각 node별 검색성능에 좋지않을 수 있다. 그렇다면 replica shard의 갯수를 결정하는 replica 값은 어떻게 설정하고, 어떠한 역할을 하는 것일까?
replica
 replica를 한 마디로 정의하면
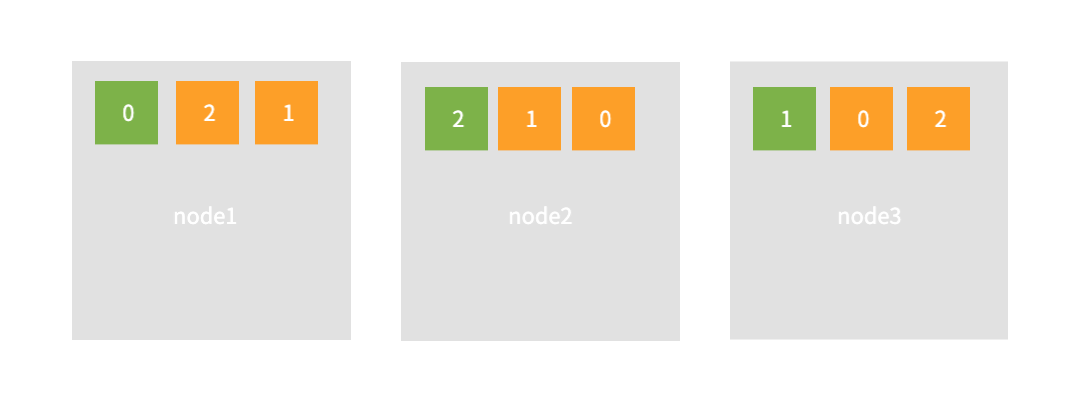
replica를 한 마디로 정의하면 shard의 복제된 갯수 로 정의 할 수 있다. 만약 primary shard가 3일때, replica를 2로 설정하면 replica shard의 갯수는 6개로, 총 9개의 shard가 존재한다는 뜻이다. 이때 replica shard는 절대 primary shard와 동일한 데이터를 갖도록 node 내에서 존재 할 수 없다. 그래서 위 그림 처럼 초록색의 primary shard와 다른 번호로 주황색의 replica shard들이 각 node에 배치된 모습을 볼 수 있다.
replica shard는 각 node에 분산된 primary shard의 복제 역할을 함으로써 두가지 장점의 기능을 갖게 된다. 먼저 특정 node로부터 온 요청사항을 다른 node에 찾는 번거로움 없이 primary shard와 함께 온전히 지원할 수 있음으로써 검색성능 향상(search performance)을 기대할 수 있다. 그리고 node 자체에 장애가 발생하더라도 서비스에는 문제 없도록 장애복구(fail-over) 역할을 할 수 있다. 위 그림에도 node 1~3중 하나가 문제 생기더라도 primary, replica shard 관계없이 각각의 node의 shard가 전체 데이터인 0~2번까지 모두 서비스 될 수 있기 때문이다. 만약 위 상황에서 3개의 node중 2개가 모두 장애가 발생한다면 자연스럽게 남은 하나의 node에 있는 replica shard들이 모든 primary shard의 역할을 하는것이다.
replica 값 설정
위 내용을 유추해보면 node는 결국 최소 2개는 있어야 하나의 node가 장애가 났을때 최소한의 fail-over이 가능하며, 이때 replica는 최소 1이상 설정해야 primary shard의 역할을 대신 할 수 있다. 즉 replica 값은 아래와 같이 정리할 수 있다. 물론 디테일한 설정은 서비스 운용 상황에 따라 모두 다르다.
replica의 최소 값은 1, 최대 값은 전체 node 갯수 - 1
replica 수가 많다고 무조건 좋은건 아니다. replica가 많아질 수록 색인 성능은 떨어지고, 읽기 성능은 좋아진다. 복제된 공간만큼 데이터 정보를 채워 넣어야하니 색인(indexing)성능은 자연스럽게 떨어지며, 특정 node에 온 요청을 해당 node의 shard에서 모두 처리 가능하게 설정함으로써 읽기 검색성능 향상을 기대할 수 있다.
실제 설정 예시
그렇다면 실제 적용한 예시(index, ip, node는 임의로 변경) 상황을 보자. shard 수를 몇개씩 설정할 정도로 꼭 수십기가의 데이터를 저장한 예시가 아닌, 정말 작은 데이터에서도 elasticsearch를 활용하기 위해 색인을 한 경우다.
GET _cat/shards/index-v2?pretty&v
간단한 shard 상태를 조회하는 qeury를 통해 현재 샤드의 상태 및 정보들을 알 수 있다.
index shard prirep state docs store ip node
index-v2 0 p STARTED 24008 25mb x.x.x.x node1
index-v2 0 r STARTED 24008 25.1mb x.x.x.x node3
index-v2 0 r STARTED 24008 25mb x.x.x.x node10
index-v2 0 r STARTED 24008 25mb x.x.x.x node6
index-v2 0 r STARTED 24008 25mb x.x.x.x node4
index-v2 0 r STARTED 24008 24.9mb x.x.x.x node9
index-v2 0 r STARTED 24008 25.1mb x.x.x.x node7
index-v2 0 r STARTED 24008 25.1mb x.x.x.x node5
index-v2 0 r STARTED 24008 25.2mb x.x.x.x node8
index-v2 0 r STARTED 24008 25.1mb x.x.x.x node2
결과로 나온 index-v2 index의 shard에 대한 현재 스펙은 아래와 같다.
- node: 10개
- shard(primary): 1
- replica: 9
- doument: 24,008개
- store(avg): 25mb
공식 문서나 블로그에 예시로 많이 설명되는 정보와 다르게 매우 작은 2만5천개의 문서인 25메가바이트 정보로도 elasticsearch의 장점을 활용하기 위해 index를 만들어 활용하고 있다. shard의 갯수가 1인것은 당연한 이유이다. 용량이 매우 적기 때문이다. 그렇다면 replica 수는 왜 9개나 되는것일까? 사실 이보다 적어도 상관 없다. 다만 현재 운용중인 node의 갯수가 10개이며, primary shard를 제외하고 남는 node에 모두 검색성능 향상을 위해 replica를 두고 싶은 이유이다.
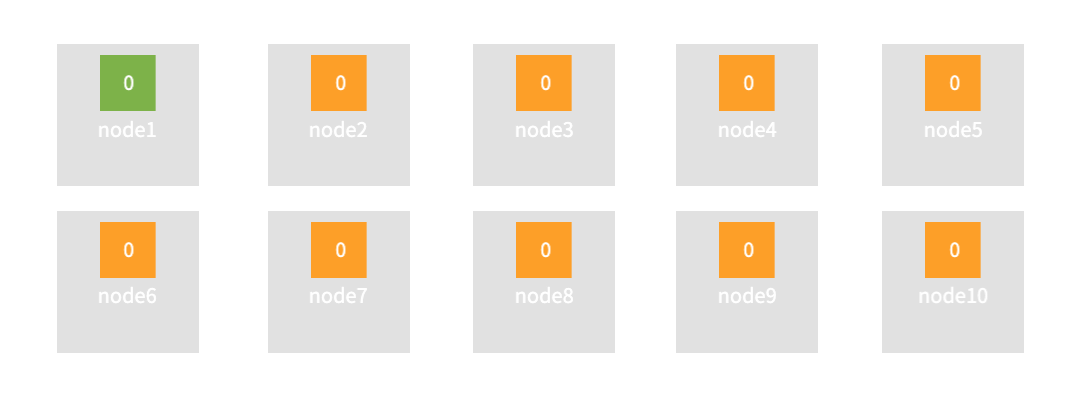
그림으로 보면 이런 느낌이 아닐까 싶다. 되게 어색해 보일 수 있지만 현재 운용중인 10개의 node를 최대한 활용하여 검색성능은 최대로 끌어올릴 수 있다. 또한 primary shard가 자리잡은 node1이 장애가 발생하더라도 나머지 9개의 node들이 replica shard에 의해 primary shard 역할을 할 수 있는 형태이다. 그렇다면 위에서 언급한대로 replica의 수가 너무 많으면 색인 속도가 늦어질 수 있지 않는가? 그럴순 있다. 하지만 이 또한 서비스 운용에 따라 선택하면 된다. 해당 서비스의 index 색인은 빈번하게 일어나지 않는 도메인이기 때문이다. 그저 색인 성능에 상관없이 검색성능과 운영 관점에 초점을 맞추어 replica 갯수를 설정했기 때문이다.
그래서?
shard와 replica는 운영 관점에서 매우 중요한 역할을 한다. 어떻게 값을 설정하느냐에 따라 검색속도나 운영에서 미치는 영향이 매우크다. 그래서 elasticsearch의 shard와 replica 값을 설정함에 있어서 정리하자면 아래와 같다.
어느정도 가이드된 범위 내에서 서비스 도메인 별로 검색성능과 fail-over 관점을 잘 고려하여 각자 운영에 맞는 입맛대로 설정하면 된다.
ref.
- https://aws.amazon.com/ko/blogs/database/get-started-with-amazon-elasticsearch-service-how-many-shards-do-i-need/
- https://brunch.co.kr/@alden/39
- https://fdv.gitbooks.io/elasticsearch-cluster-design-the-definitive-guide/content/a-few-things-you-need-to-know-about-lucene.html
- https://esbook.kimjmin.net/03-cluster/3.2-index-and-shards
