그래서 대용량 트래픽은 어떻게 처리할까?
대용량 트래픽 처리는 서버 개발자들의 면접 단골 질문이자, 서버 개발자들이라면 한번쯤 고민해보는 그 주제이다. 사실 주어진 환경과 시스템에 따라 처리할 수 있는 방향과 방법이 무궁무진하다. 때로는 매우 쉬운 조치만으로도 가능해질 수 있다면, 때로는 시스템 아키텍처 전체를 뒤엎어야 하는 대공사를 해야할 수 있다. 일반적으로 고려하면 좋을 방법들을 알아보자.
대용량 트래픽 처리
대용량 트래픽은 말 그대로 단위 시간의 수 많은 요청을 뜻한다. 구글이나 페이스북과 같은 기업들은 초당 수십억 건 이상의 요청이 올 수 있으며, 일반 국내 기업에서도 초당 수천에서 수만 이상의 요청이 올 수 있다. 어느정도 트래픽이 대용량일지 정의한 수치는 따로 없다. 그냥 내 개인적인 생각이라면, 인프라 또는 데브옵스 조직이 있는 회사라면 어느정도 시스템 규모 및 트래픽이 있고, 이에 따른 전체적인 시스템 및 트래픽 관리를 하는게 아닐까 싶다.
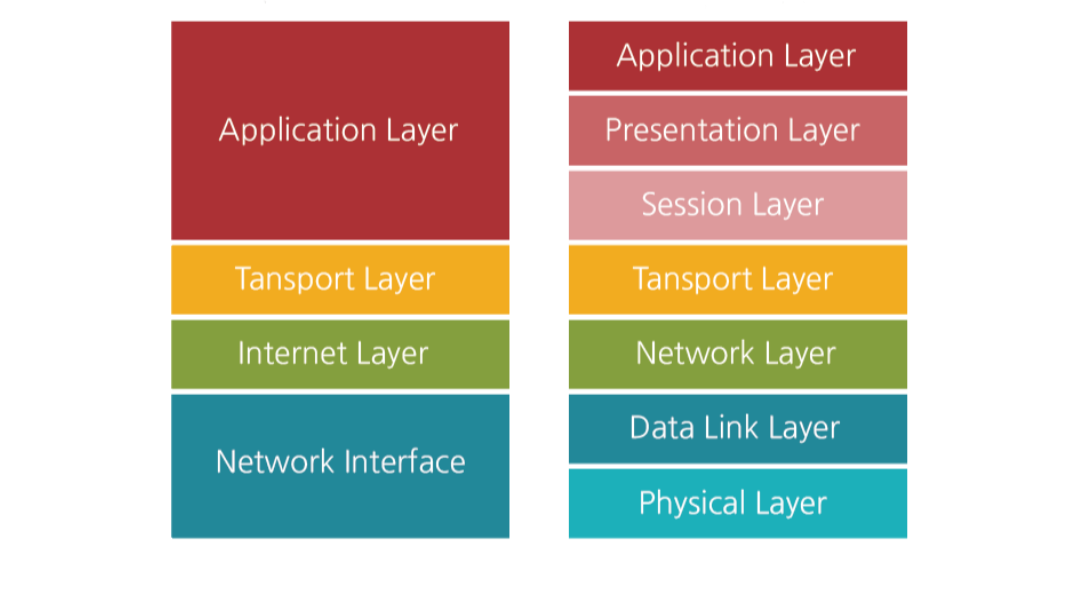
수천 수만의 대용량 트래픽을 단순하게 생각하면, 하나의 트래픽을 짧은 시간에 아주 많이 처리하는 것이다. 결국 하나의 트래픽은 하나의 네트워크 통신에 의해 처리된다. 즉, TCP/IP 통신간에 병목이 발생될 수 있는 부분을 최적화 한다면 곧 대용량 트래픽을 처리할 수 있는 방법이 아닐까 싶다. 개발자로써 우리가 할 수 있는 역할은 application layer에서 병목을 최소화 시키고 최적화할 수 있는 방법을 찾는 것이다.
scale in/out
뭐든 그렇듯 장비빨이 최고다. 가장 쉽지만 비용을 고려해야하는 방법이다. 트래픽 대군에 맞서 싸우기 위해 장비를 강화(sacle in)하거나 비슷한 장비를 여러개 장착(sacle out)하는 것을 선택해야 한다. 둘중 쉬운 방법은 성능이 빵빵한 장비를 사용하는 sacle in이다. 하지만 일정 성능 이상부터는 기하급수적으로 비싸진다. 그래서 일반적으로 가성비 좋은 장비를 여러대 장착시키는 형태의 sacle out을 많이 선택한다. 그렇다면 장비를 얼마나 늘리면 되는걸까? 트래픽의 정도를 예측하기 위해서는 대역폭(bandwidth)을 계산 해야한다.
bandwidth
대역폭은 서버에서 전송 가능한 데이터의 양을 의미하며, 초당 전송 가능한 데이터의 양을 측정한 값이다. 즉, 서버가 어느정도의 대역폭이 확보되어 있냐에 따라 일단 대량의 요청을 버틸 수 있냐 없느냐가 결정 되는 것이다. 트래픽 대군이 몰려올때 맞서 싸울 아군의 전력이 얼마나 확충되어 있는지를 알아야한다.
서버 개발자들에게는 긴장의 순간들이 있다. 바로 이벤트, 프로모션 등의 순간 트래픽이 많을 수 있는 페이지다. 이러한 경우 서버가 안정적으로 트래픽을 받을 수 있는 상태인지 확인해야한다. 즉, 대역폭을 확인하는 것이다. 예시로 티몬의 룰렛 서비스를 보자. 해당 페이지를 예시로 드는 이유는 몇년 전 과거, 주니어 개발자였던 내가 만든 페이지기 때문이다. (머쓱)
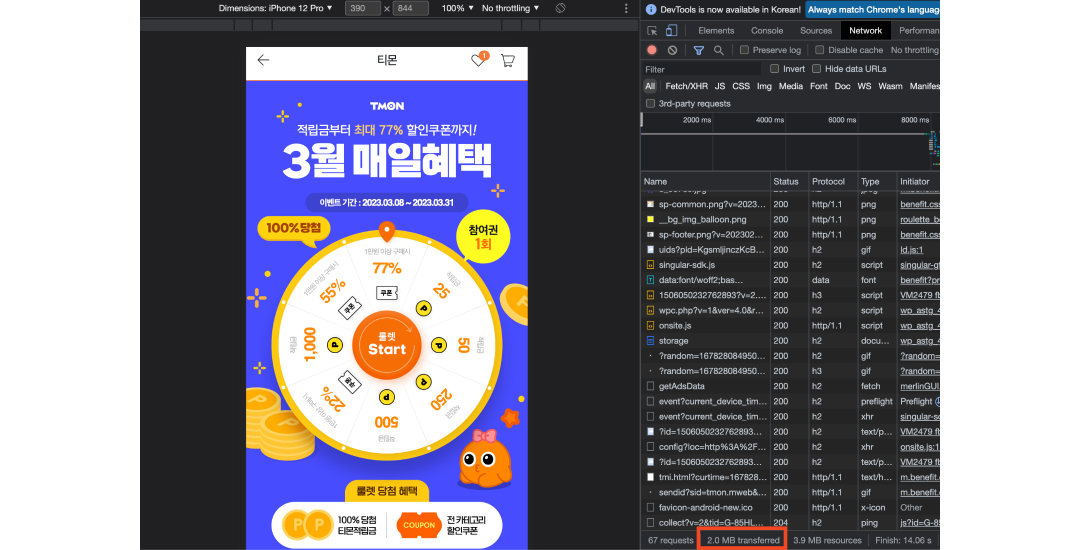
chrome의 Network 탭의 하단에서 정적 콘텐츠를 모두 합산하여 해당 페이지의 네트워크 전송량이 얼마인지 대략 알 수 있다. 예시 페이지는 2MB로 나오고 있다. 해당 값은 HTTP 캐시를 모두 비운 최초 로드값이다. 만약 해당 페이지에 2만명의 유저가 동시에 1번만 1분 내에 접근 한다면 해당 페이지는 정상적으로 운영될 수 있을까? 물론 정답은 알 수 없다. 왜냐면 해당 페이지를 내가 개발 할 때로부터 수년이 지난 지금, 해당 웹서버의 스펙을 모르기 때문이다. 그렇다면, AWS EC2기준 어느정도 스펙의 타입을 선택하면 될 지 역산해보자.
2MB * 20,000명 * 1회 = 40,000MB(=40GB)
단순 트래픽은 총 40GB 발생하며, 이를 1분내에 완료 가능한지 확인하려면 대역폭으로 환산해야한다. 참고로 Bytes에서 bit로 변환하기 위해 트래픽 총량에 8을 곱해야한다.
40GB * 8 / 60s = 5.33Gbps
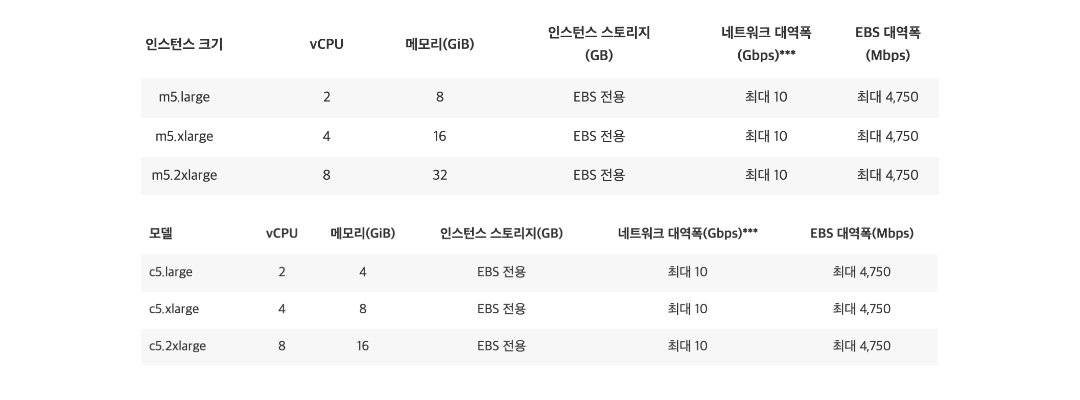
위 시나리오 정도의 트래픽을 감당하기 위해선 적어도 AWS EC2 기준 m5, c5 정도 스펙은 가용해야 적어도 트래픽을 수용은 할 수 있다고 예상해볼 수 있다. 물론 이는 다른 장애 및 병목 포인트는 고려하지 않고, 단순히 서비스 페이지 전송량으로만 계산한 것이다. 그렇다면 조금 더 전송량이 높은 페이지를 개발하고, 사용자 수가 많아지면 더 높은 고가용성 서버를 사용해야할까? 무조건 정답은 아니다. sacle out을 하는 이유는 가성비 좋은 장비를 여러대두어 부하를 분산시키기 위함이다.

고가용성 장비에 대한 금전적 부담 때문에 스펙을 낮추어 t3를 사용하면 어떨까? (이론상 CPU, Memory의 변화는 무시) 최대 5Gbps를 갖는 t3 대역폭 스펙으로는 시나리오 결과의 5.33Gbps의 대역폭을 버틸 수는 없다. 하지만 해당 t3서버를 2대 두고 로드밸런서를 통해 부하를 분산한다면 어떨까? 이론상 최대 10Gbps 대역폭을 수용할 수 있게 되는 것이다.
load balancer
sacle out으로 서버를 증설했다면 로드밸런서를 통해 트래픽을 분산시켜 서버의 부하를 줄일 수 있다. 로드밸런서을 이용하면 한 서버가 다운되더라도 이중화시킨 다른 서버에서 서비스를 지속하여, 사용자들이 문제를 인지하지 못하게 할 수 있다. 이는 곧 부하분산 뿐 아니라, 장애대응 효과까지 덤으로 얻을 수 있다.
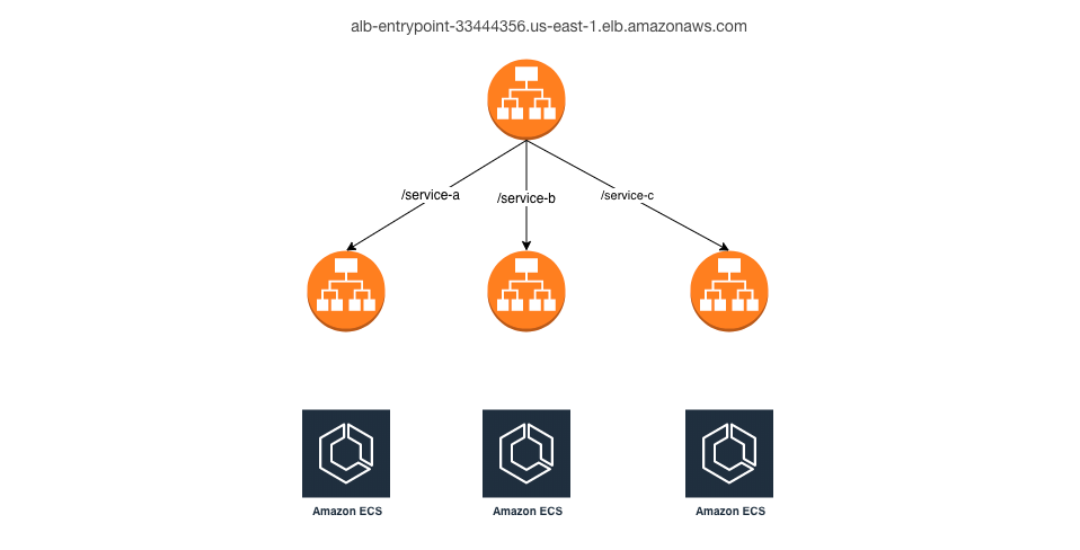
로드밸런서는 대표적으로 TCP/UDP 기반의 L4, HTTP/HTTPS 기반의 L7 계층의 로드밸런서가 있다. AWS에는 L7 ALB(Application Load Balancer) 서비스를 제공한다. ALB는 HTTP/HTTPS 기반으로 동작하여 URI 경로, host 이름, HTTP header, query 문자열 등 다양한 속성을 기반으로 요청을 분배하여 L4 로드밸런서에 비해 세밀한 부하 분산이 가능하다. 그외 방화벽과 결합, 프록시 서버의 역할 등의 기능도 수행할 수 있다.
HTTP
하나의 트래픽은 곧 TCP/IP HTTP 통신을 통해 처리되는 것이라 했다. 결국 HTTP 통신간에 지연을 줄일 수 있다면, 단위 시간에 처리할 수 있는 요청 수도 많아질 수 있다. 방법은 단순하다. HTTP version을 상향 시키는 것이다.
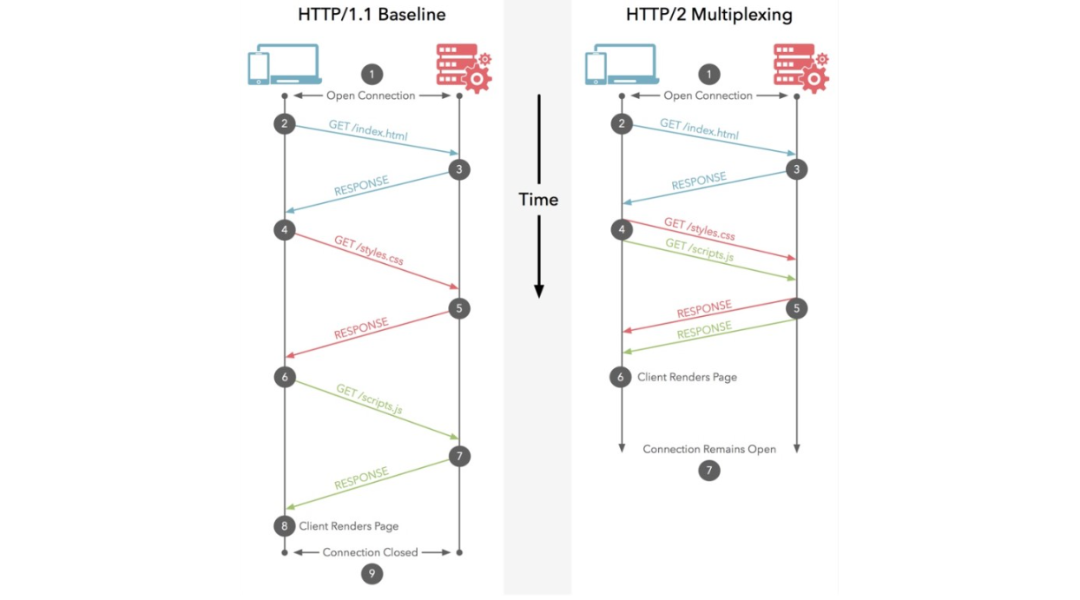
만약 가용중인 웹서버가 HTTP/1.1을 사용하고 있다면, HTTP/2.0으로 버전을 올리는것 만으로도 성능이 향상될 수 있다. HTTP/2.0은 한번의 연결로 여러 요청을 처리할 수 있는 멀티플렉싱을 제공함으로써, 단위 시간에 더욱 많은 요청을 처리할 수 있기 때문이다. 다만 자신이 사용중인 웹서버 및 클라이언트(브라우저)에서 HTTP/2.0을 지원하는지 확인해야한다. nginx 기준으로는 1.9.5 버전 이상에서 HTTP/2.0를 지원한다. 참고로 구글에서 개발한 UDP 기반의 HTTP/3.0도 이미 시장에서 상용되고 있으니 관심 있으면 더 깊게 찾아봐도 좋다.
storage
웹서버의 성능을 높이거나 갯수를 늘려도 데이터 저장소에 의해 트래픽을 처리하지 못할 수 있다. 네트워크 시간중 I/O 처리를 얼마나 안정적이고 빠르게 처리하냐에 따라 서버 가용성에 큰 도움이 된다. 가장 쉽게 접근하는 RDBMS인 DB의 부하 분산 방법부터 알아보자.
DB
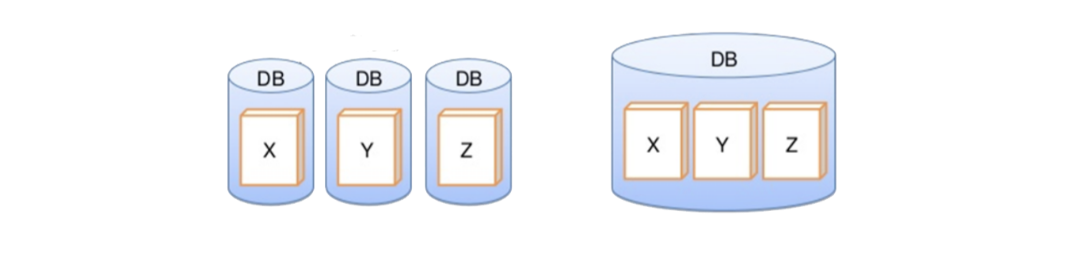
- sharding: 대량의 데이터를 가진 테이블을 수평적으로 여러 DB로 분할하여 저장하는 방식이다. 읽기 및 쓰기를 여러 분할한 샤드로 분산처리할 수 있다. 다만 join 연산은 서로 다른 DB에서는 할 수 없으니, join이 필요 없는 단일 도메인 대상의 테이블에 적합하다.
- partitioning: 대량의 데이터를 가진 테이블을 수직(또는 수평)으로 여러 테이블로 분할하여 저장하는 방식이다. 다만 말그대로 테이블을 쪼개는 만큼, join할 key를 설정해야하며 join 연산을 해야하는 비용이 발생될 수 있다.
- index: 인덱스는 검색, 정렬, 그룹 등을 도와주는 DB에서 중요한 역할을 하는 자료구조이다. 샤딩과 파티셔닝을 하게되면 대량의 테이블이 경량해질 수 있다. 이는 곧 자연스럽게 인덱스 성능이 올라가는 효과를 볼 수 있다.
cache
일반적으로 mysql과 같은 DB는 디스크 기반의 데이터 스토리지이기 때문에 메모리에 비해서 훨씬 느린 속도로 데이터를 탐색한다. 그래서 반복되는 요청 리소스는 메모리 캐시를 통해 처리하여, 서버 부하를 줄일 수 있다. 메모리 캐시는 일반적으로 redis와 같은 nosql을 활용할 수 있다.
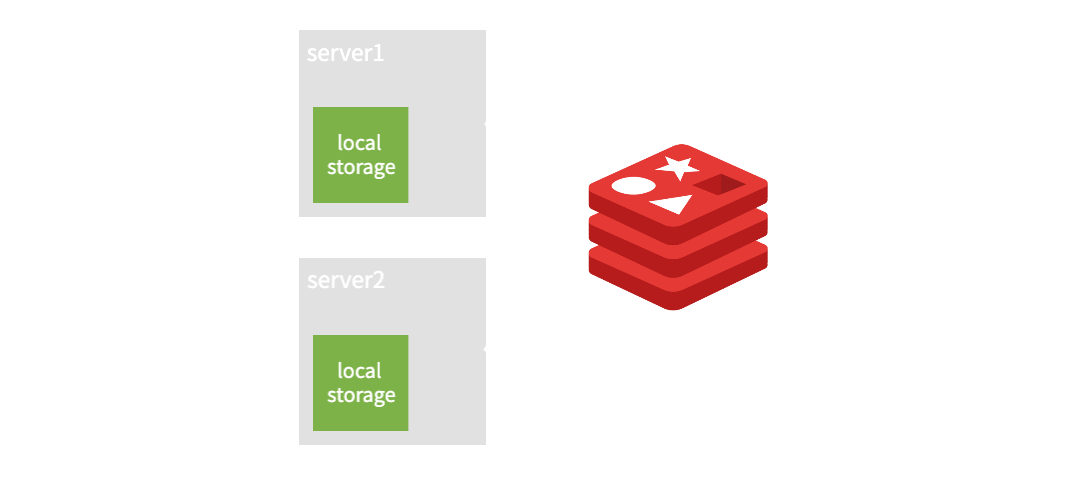
캐시는 적용하고자 하는 도메인 데이터의 성질 local cache, global cache 전략중에 선택할 수 있다.
- local cache: 기동중인 서버 내에 캐시 메모리를 사용하는 것이다. 사실상 오버헤드가 없다. 서버가 여러대면 각 서버마다 독립적인 캐시 메모리를 할당 받기 때문에 가장 빠르게 응답을 받을 수 있다. 다만 캐시의 동기화가 복잡할 수 있고, 각 서버간에 일관성이 깨질 수 있다.
- global cache: 여러대의 서버가 있다면, 별도의 캐시 서버두고 동기화된 메모리를 공유하는 것을 뜻한다. local cache에 비하면 동기화 문제는 없으나 네트워크 I/O 과정이 있기에 속도차이는 발생할 수 있다.
CDN
일반적인 데이터는 서버의 메모리 캐시를 통해 처리한다면, 컨텐츠 정보는 CDN(Content Delivery Network)을 통해 저장 또는 캐시 할 수 있다.
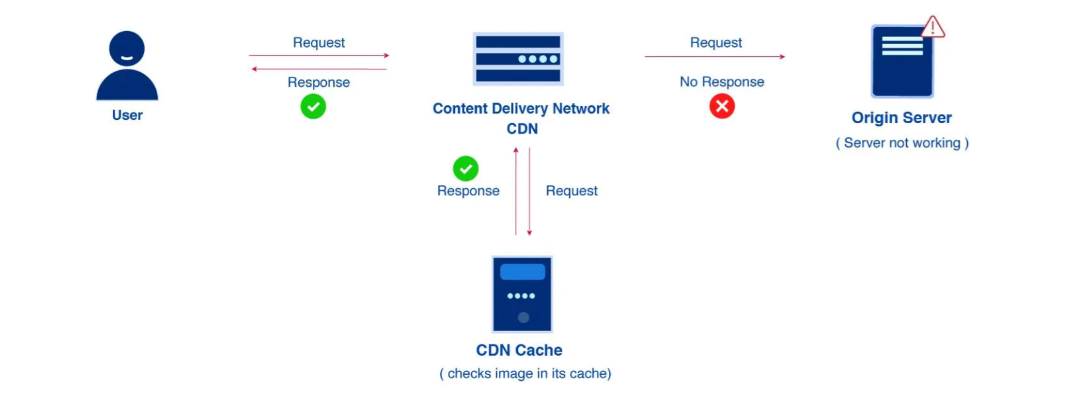
CDN은 서버와 사용자 사이에서 동영상이나 웹사이트 이미지와 같은 컨텐츠 정보를 빠르게 전달하기 위한 일종의 캐시 서버이다. 컨텐츠 정보에 특화되어 관리되므로 안정적으로 컨텐츠 정보를 전달할 수 있다. 또한 웹 서버의 컨텐츠 트래픽을 부하분산 함으로써 웹 서버 자체에 대한 대역폭 소비를 줄여 성능과 가용성 측면에서 많은 이득을 볼 수 있다. 논외로, 세계에서 가장 점유율이 높은 CDN은 Akamai이며, AWS에는 CloudFront 라는 서비스로 제공한다.
application
개발자가 직접적으로 고민해야 할 영역이다. 항상 시스템을 모니터링하고 테스트하면서 병목이 발생될 수 있는 부분을 리펙토링 하도록 노력해야한다. 경량한 서비스를 만들기 위해서는 도메인 목적에 맞게, 단일 책임 기반의 시스템 설계 및 개발이 필요하다.
big O
시간복잡도가 O(n^2) 이상이거나 입력 크기가 큰 데이터를 처리해야 하는 로직이라면, 항시 경계 해야한다. 자고로 10,000건의 데이터를 중첩된 for loop로 개발하게 되면 100,000,000(1억)건의 반복을 동기적으로 수행해야 한다. 물론 처음부터 대량 정보에 대해 중첩된 반복으로 개발하진 않을것이다. 하지만 시스템에 관심을 기울이지 않는다면, 어느새 늘어나있는 테이블 데이터에 의해 내가 만든 비즈니스 로직이 전체 네트워크에 병목을 줄 수 있다.
pool size
여러 도구에 따라 pool(대기열)을 지원하는 시스템이 있다. 특히 대용량 트래픽을 처리하기 위해서는 충분한 CPU, 메모리, 디스크 리소스를 확보하여 thread pool 및 DB connection pool 값을 적절하게 설정해야 한다.
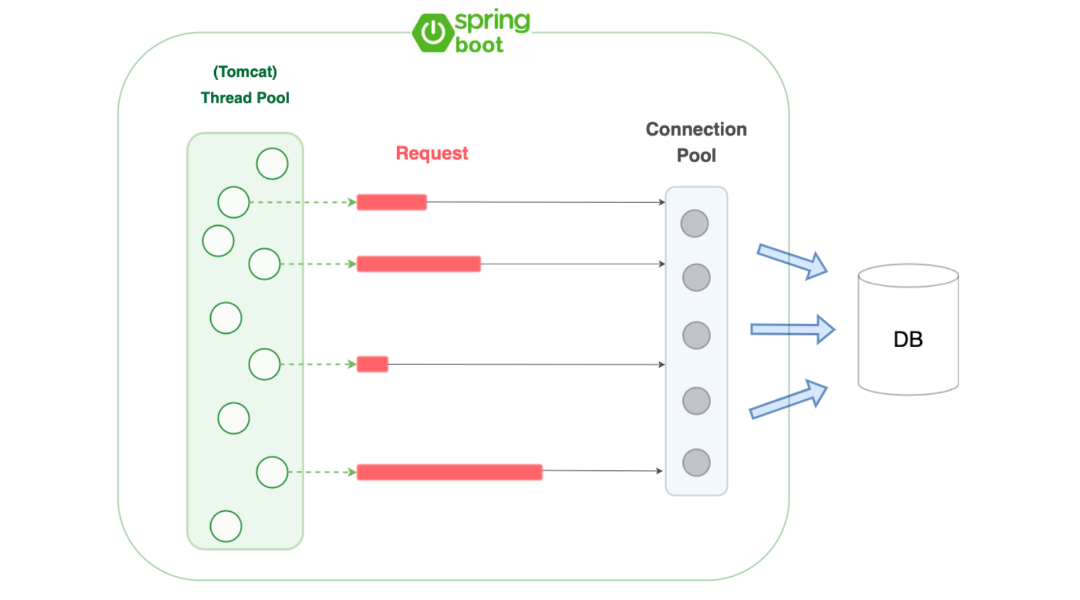
- thread pool: 애플리케이션에서 처리해야 할 작업을 동시에 처리할 수 있도록 지원하는 스레드의 집합이다. 너무 적게 설정하면 대기중인 작업이 많아지게 되어 처리 속도가 느려질 수 있다. 반대로 너무 많이 설정하면 스레드는 별도의 스택 공간을 갖기 때문에 메모리를 많이 잡아먹으며, 잦은 context switching이 발생하여 CPU 오버헤드 등의 문제가 발생할 수 있다. 참고로 spring boot의 기본 WAS인 tomcat의 경우 default thread pool size는 200이다.
- DB connection pool: DB에 동시 연결이 가능한 수 이다. java의 DB connection 과정은 I/O과정에 부하가 큰 작업이다. 그래서 미리 connection pool을 통해 서버 연결간에 connection을 확보하고, 재활용 함으로써 서버의 부하를 줄일 수 있다. 너무 적게 설정하면 대기 시간이 발생하여 애플리케이션의 처리 속도가 느려질 수 있고, 너무 많이 설정하면 메모리 소모가 클 것이다. 참고로 spring boot의 경우 HikaraCP를 기본 커넥션 관리 라이브러리로 사용한다.
CQRS
애플리케이션 서버를 경량화하고 목적에 맞는 커넥션(read, write)을 관리함으로써 시스템 자원을 효율적으로 사용할 수 있다. 이는 곧 대용량 트래픽을 처리에 큰 효과를 발휘할 수 있다 있다. 이러한 시스템은 명령(command)과 조회(query)를 분리하는 것을 중심으로 설계 된 CQRS(Command Query Responsibility Segregation) 소프트웨어 아키텍처 패턴을 통해 구현할 수 있다.
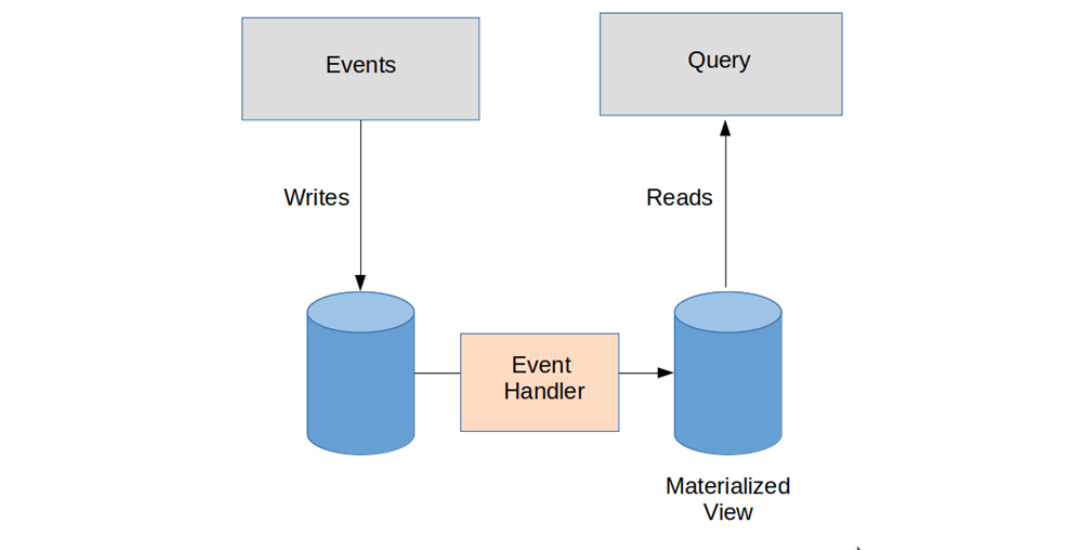
CQRS 패턴은 데이터의 변경을 명령(command)하는 시스템과 조회(query) 및 처리하는 시스템을 분리하는 것이 핵심이다. 각각 분리된 시스템은 분산 시스템으로써의 장점을 갖을 뿐 아니라, 확장성 및 유지보수성 등 여러가지 측면에서 이점이 있다. 일반적으로 이벤트 기반의 시스템(kafka, rabbitMQ 등) 및 DDD(Domain-driven Design) 개념과 함께 사용한다.
REST API와 같은 직접적인 http connection에 의한 처리를 하지 않기 때문에, query의 역할을 하는 시스템에서의 장애를 command 시스템에서 알아내기 위해 예외적인 개발이 필요할 수 있다. 또한 비즈니스 처리가 동기적으로 진행되어야 할 DB동작과 엮이게 된다면 transaction 처리에 어려움이 발생할 수 있다.
non blocking/async
non blocking과 async를 조합하면 대량의 요청에 대해 병렬적으로 처리하여 시스템 처리량을 향상시킬 수 있다. non blocking이 비동기로 동작하는 것이 아닌가? 라고 생각하는 경우가 많다. 비동기 동작은 asynchronous이다. 두 개념은 다른것이며, 설명은 아래와 같다.
- non-blocking: A 함수가 B 함수를 호출 할 때, B 함수가 제어권을 바로 A 함수에게 넘겨주면서, A 함수가 다른 일을 할 수 있도록 하는 것.
- asynchronous: A 함수가 B 함수를 호출 할 때, B 함수의 결과를 B 함수가 처리하는 것.
사실 이런 딱딱한 설명으로는 이해하기 힘들 수 있다. 그림을 보면서 이해해보자.

커피 가계 직원은 커피를 주문한 손님이 다른일을 할 수 있도록 non blocking으로 주문 후 이후 행동에 대한 제어권을 손님에게 주는 것이다. 손님은 잠깐 나갔다 오던 의자에 앉아 있던 화장실을 다녀오던 하고싶은 일을 하면된다. 그리고 커피를 직원이 손님에게 가져다 주지 않고, 진동벨을 통해 손님이 받으러 간다. 즉, 손님이 주문 결과 나온 커피를 직접 받도록 async로 동작한다. 그래서 스타벅스는 non blocking/async로 동작하기 때문에 주문 순환이 빠르다. 그래서 대량의 손님(트래픽)을 빠른 시간에 처리할 수 있는 것이다.
하지만 첫번째 손님이 5분이 걸리는 음료를 주문하고, 세번째 손님이 1분이 걸리는 음료를 주문한다면 어떨까? 세번째 주문한 손님의 진동벨이 먼저 울릴 수 있다. 하지만 진동벨은 울리고 있지만, 전화를 하던 도중이라 나중에 음료를 받으러 갈 수도 있다. 즉, async에 대한 동작은 커피(결과)에 대한 제어권이 손님에게 있기 때문에 최종적인 결과에 대한 순서를 보장할 수 없다.
그래서?
대용량 트래픽을 처리할 수 있는 방법은 사실 소개한 방법들 외에도 너무나 많다. 실제로 상황에 처해보면 예상치 못한 곳에서 수 많은 체크 포인트들이 발생할 수 있다. 결국 주어진 상황에서 최선의 방법을 찾아서 대응 해야한다.
대용량 트래픽 처리는 서버 개발자들의 워너비이자 숙명이다.
ref.
- https://vince-kim.tistory.com/m/39
- https://docs.aws.amazon.com/ko_kr/elasticloadbalancing/latest/application/introduction.html
- https://blog.naver.com/PostView.nhn?blogId=dilrong&logNo=221689556862
- https://jaehoney.tistory.com/155
- https://imagekit.io/blog/what-is-content-delivery-network-cdn-guide/
- https://poiemaweb.com/js-async
- https://aws.amazon.com/ko/blogs/korea/new-application-load-balancer-simplifies-deployment-with-weighted-target-groups/
